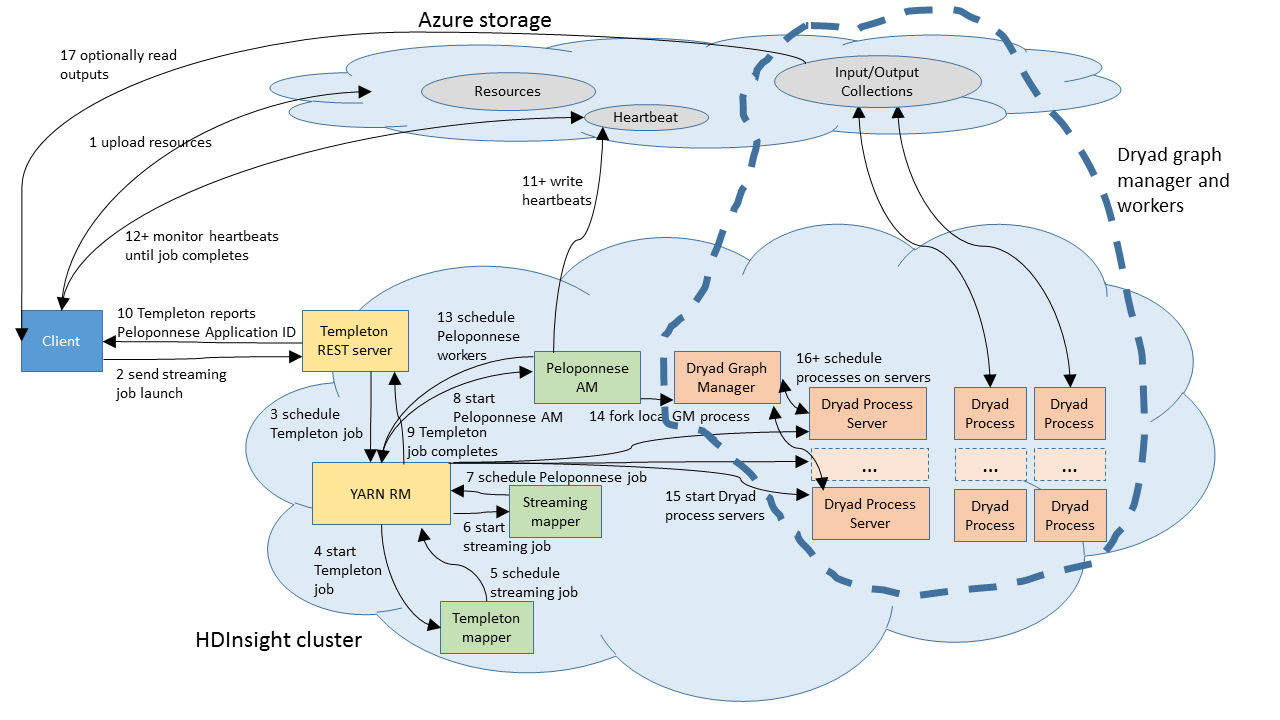
The process for running a DryadLINQ application on HDInsight 3.0 is a bit complicated. This is because HDInsight does not expose all of the "raw" Hadoop 2.2 protocols to clients outside the cluster. In particular, the only way to launch a job on a cluster is using the Templeton REST APIs, as nicely wrapped up in the Microsoft .NET SDK for Hadoop. Unfortunately, right now Templeton does not support native YARN applications like DryadLINQ, and so the only jobs that may be launched from outside the cluster are Hadoop 1 jobs (MapReduce, HIVE, Pig, and so on).
What happens when your client program runs a job
The client DryadLINQ program determines all of the resources that will be needed in the job. It checks to see if they are already present on the cluster (using a hash of the binary) and uploads any that are not present. They are uploaded to the default cluster storage account, so that Hadoop 2.2 services like YARN will be able to read them using wasb. (See Using Azure Blob storage with HDInsight for an explanation of how wasb/hdfs interacts with Azure blob storage.)
The client serializes a description of the DryadLINQ YARN application into an XML file. This file contains a list of the resources that the DryadLINQ Application Master needs in order to run, and a command line for the application master. (See YARN concepts for an explanation of application masters.) This XML file is uploaded to the cluster's default container as user/<yourUserName>/staging/<jobGuid>.xml.<hash>.
The client calls the .NET Hadoop SDK to run a Hadoop Streaming job using the above XML file as input.
The .NET SDK calls the Templeton REST API on your cluster.
The Templeton REST server launches a MapReduce job called TempletonControllerJob on your cluster.
The controller job launches a second MapReduce job called streamjob<someNumber>.jar on your cluster.
The streaming job reads the XML serialized above, and launches the DryadLINQ YARN application master, which then actually runs your program. The title of the DryadLINQ application is DryadLINQ.App by default, but you can set it to something more friendly using the JobFriendlyName property of the DryadLinqContext.
The streaming job writes the YARN application Id for the DryadLINQ application back to the cluster's default container as user/<yourUserName>/staging/<jobGuid>/part.00000.
The DryadLINQ application writes heartbeat, logging and status information into a container called dryad-jobs/<yarn-application-id> in the cluster's default storage account.
The client code reads the application id from user/<yourUserName>/staging/<jobGuid>/part.00000 and then monitors dryad-jobs/<yarn-application-id> to get updates on the progress of the job. This is also where the job browser gets its information about the job.
If you Enable Remote Desktop on your HDInsight cluster, and click on the Hadoop YARN Status shortcut link on the desktop, you can see all these jobs running.
Unfortunately because of the current configuration of HDInsight clusters, all DryadLINQ logs are archived immediately when the application exits, and you will get a "Failed redirect for container" error if you try to navigate to the logs of a completed application. We have tried to report errors in user application code back so that they are visible in the DryadLINQ Job Browser to avoid the need to consult the logs. If you do need to consult the logs, remote desktop to your HDInsight cluster, then click on the Hadoop Command Line link on the desktop, and then run a command similar to yarn logs -applicationId <APPLICATION_ID> -appOwner <CLUSTER_USER_NAME> where you replace <APPLICATION_ID> and <CLUSTER_USER_NAME> with values appropriate to your job and cluster configuration.